Under-Sampling Methods for Imbalanced Data (ClusterCentroids, RandomUnderSampler, NearMiss)The imbalance of data is a big problem for classification tasks. In python, there is a library to allow to use of many algorithms to handle…Jul 15, 2021234Jul 15, 2021234
Yellowbrick; Machine Learning VisualizationVisualization is essential to make our analysis or modeling process understandable. We need visualization to see results or workflow…Apr 19, 2021404Apr 19, 2021404
Feature Selection with BorutaPy, RFE and Univariate Feature SelectionFeature selection is one of the important part of the machine learning pipeline. We may have to struggle with a lot of features or useless…Apr 4, 2021402Apr 4, 2021402
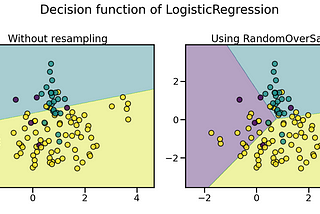
Random Resampling Methods for Imbalanced Data with ImblearnWe want the data we prepared or analyzed for the model to be perfect. However, data may have missing values, outliers, complex data types…Mar 25, 20213115Mar 25, 20213115
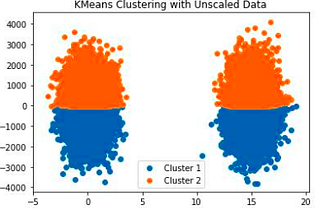
Feature Scaling with Scikit-Learn for Data ScienceIn the data science process, we need to do some preprocessing before machine learning algorithms. These can be some basic data analysis…Feb 22, 2021491Feb 22, 2021491
Model Deployment with Streamlit on AWS EC2We have already touched on the importance of model deployment and sharing this model with others. We need to share our model with…Feb 12, 20215071Feb 12, 20215071
Introduction to Streamlit for Machine Learning Web AppStreamlit is an open-source Python library that makes it easy to build beautiful custom web-apps for machine learning and data science.Feb 5, 20214081Feb 5, 20214081
Encoding with Pandas get_dummiesWe previously covered the issue of encoding and its importance. In short, machine learning models are mathematical models that use…Jan 24, 20214071Jan 24, 20214071
Label Encoding vs One Hot EncodingWe need numerical data in data science techniques such as machine learning and deep learning models. We start our analysis with…Jan 18, 20215241Jan 18, 20215241
Detecting and Handling Outliers with PandasData analysis is a long process. There are some steps to do this. First of all, we need to recognize the data. We have to know every…Jan 15, 20218199Jan 15, 20218199